

Our Research
The key questions of our research are how to model and extract general, linguistic world knowledge from large amounts of text data, and how to apply this knowledge to solve tasks that require human-like language intelligence.
Our research spans transfer learning from neural language models, "never-ending learning" to create neural networks that never stop learning, methods for text analysis across many languages, and formalisms of universal semantics.
Neural Language Modelling and Transfer Learning
We work on neural language modeling to extract linguistic knowledge from large bodies of text data to create word embeddings that can be applied to various downstream NLP tasks. Our canonical approach uses recurrent neural networks (RNNs), as shown in the Figure below:
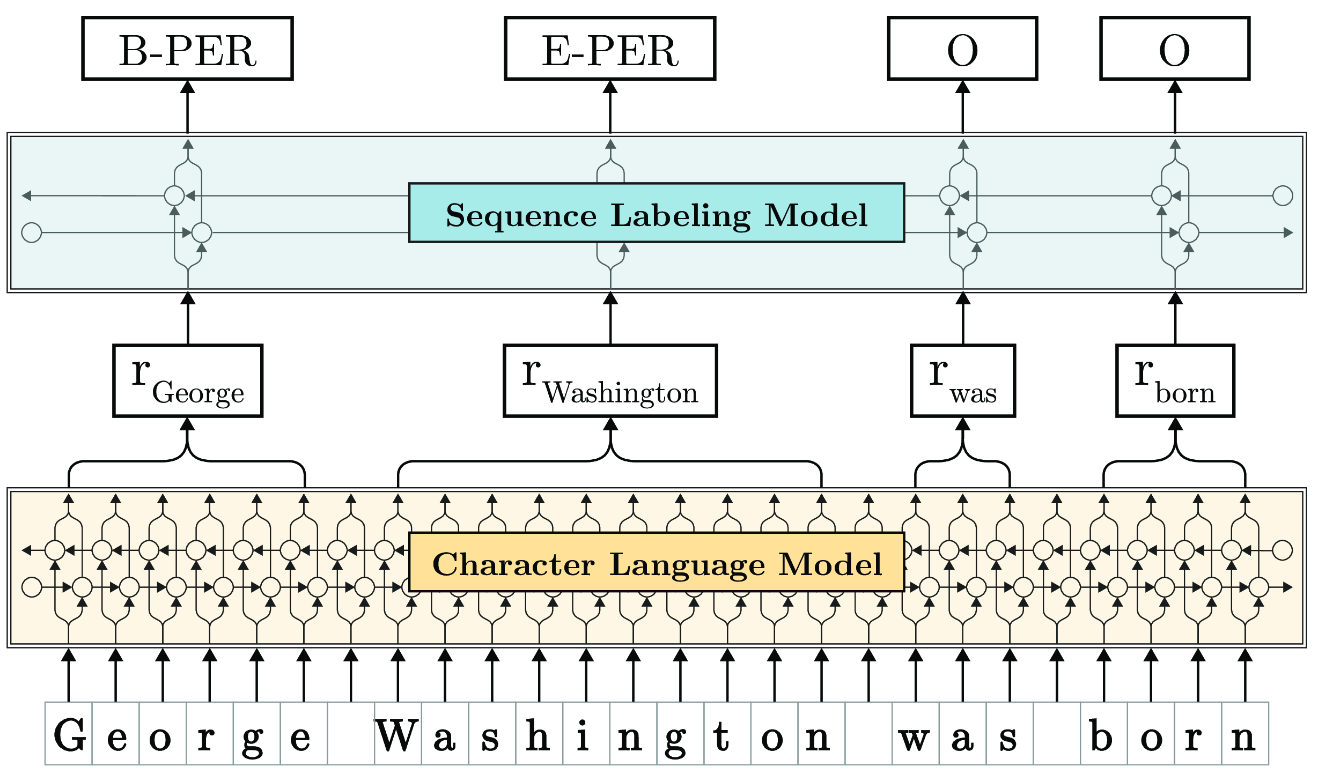
We model language as sequences of characters that are input into a bidirectional character-level language model (LM) that was pretrained on large amounts of text data. We extract the internal LM states at the word boundaries to create word embeddings for each word in a given sentence. Our approach is currently the state-of-the-art for many NLP sequence labeling tasks such as named entity recognition or part-of-speech tagging. It is also sample- and resource-efficient due to its character-level modeling. This enabled the open source community to train such Flair-Models for many langauges and domains.
More information may be found in our paper:
-
Contextual String Embeddings for Sequence Labeling. Alan Akbik, Duncan Blythe and Roland Vollgraf. 27th International Conference on Computational Linguistics, COLING 2018. [pdf]
Never-Ending Learning
Traditional machine learning splits the ML lifecycle into two phases: A training phase in which a model is trained/fine-tuned, and an application phase in which the model is applied, but no longer learns. Our research instead focuses on models that never stop learning, and so continue to learn even during the application phase.

Our recent work on pooled contextualized embeddings (siehe Figure above) is an example of this. Our approach adds a memory mechanism on top of a language model which records all occurrences of each distinct word. The representation of each word is a combination of the current sentence and the combined memory. Since this memory constantly grows - even during application - the internal knowledge of our model is constantly updated. Our paper has more information:
-
Pooled Contextualized Embeddings for Named Entity Recognition. Alan Akbik, Tanja Bergmann and Roland Vollgraf. Annual Conference of the North American Chapter of the Association for Computational Linguistics, NAACL 2019. [pdf]
Multilingual Text Analytics
We research models capable of analysing text data across multiple languages. The Figure below for instance shows the output of a (single) multilingual part-of-speech tagging model applied to text in German, English and French:

As the Figure shows, our model can correctly analyze all three languages. For instance, it recognizes nouns (green) and verbs (red). Such multilingual models are already shipped with the Flair framework und are continuously improved with our research. See:
- Multilingual Sequence Labeling With One Model. Alan Akbik, Tanja Bergmann and Roland Vollgraf. Northern Lights Deep Learning Workshop, NLDL 2019. [pdf]
Universal (cross-lingual) semantics
Next to latent spaces we also work on symbol-based representations of semantics. Our key project are the Universal Proposition Banks which we develop together with IBM Research. Goal is to create a formalism that captures semantics expressed in arbitrary languages in a unified symbol-based system.
For example, consider the three sentences in German, Finnish and Chinese below. All three sentences use the semantic concept of ordering something. Our parsing system can detect this semantic frame in all three sentences:

The result of our research are the Universal Proposition Banks that specify the formalism and allow researchers to train their own semantic role labeling systems.
More information may be found in our papers:
- Generating High Quality Proposition Banks for Multilingual Semantic Role Labeling. Alan Akbik, Laura Chiticariu, Marina Danilevsky, Yunyao Li, Shivakumar Vaithyanathan and Huaiyu Zhu. 53rd Annual Meeting of the Association for Computational Linguistics, ACL 2015. [pdf]
- Towards Semi-Automatic Generation of Proposition Banks for Low-Resource Languages. Alan Akbik and Yunyao Li. 2016 Conference on Empirical Methods on Natural Language Processing, EMNLP 2016.
- Multilingual Aliasing for Auto-Generating Proposition Banks. Alan Akbik, Xinyu Guan and Yunyao Li. 26th International Conference on Computational Linguistics, COLING 2016. [pdf]
- The Projector: An Interactive Annotation Projection Visualization Tool. Alan Akbik and Roland Vollgraf. 2017 Conference on Empirical Methods on Natural Language Processing, EMNLP 2017. [pdf][video]